
Actualizado:
Un genoma es el conjunto de instrucciones de ADN que ayuda a cada ser vivo a desarrollarse y funcionar. Las secuencias del genoma difieren ligeramente entre los individuos. En el caso de los humanos, los genomas de dos personas son más del 99% idénticos. Las pequeñas diferencias restantes contribuyen a la singularidad de cada persona y ofrecen, por ejemplo, información sobre la salud, ayudando a diagnosticar enfermedades y desarrollar tratamientos.
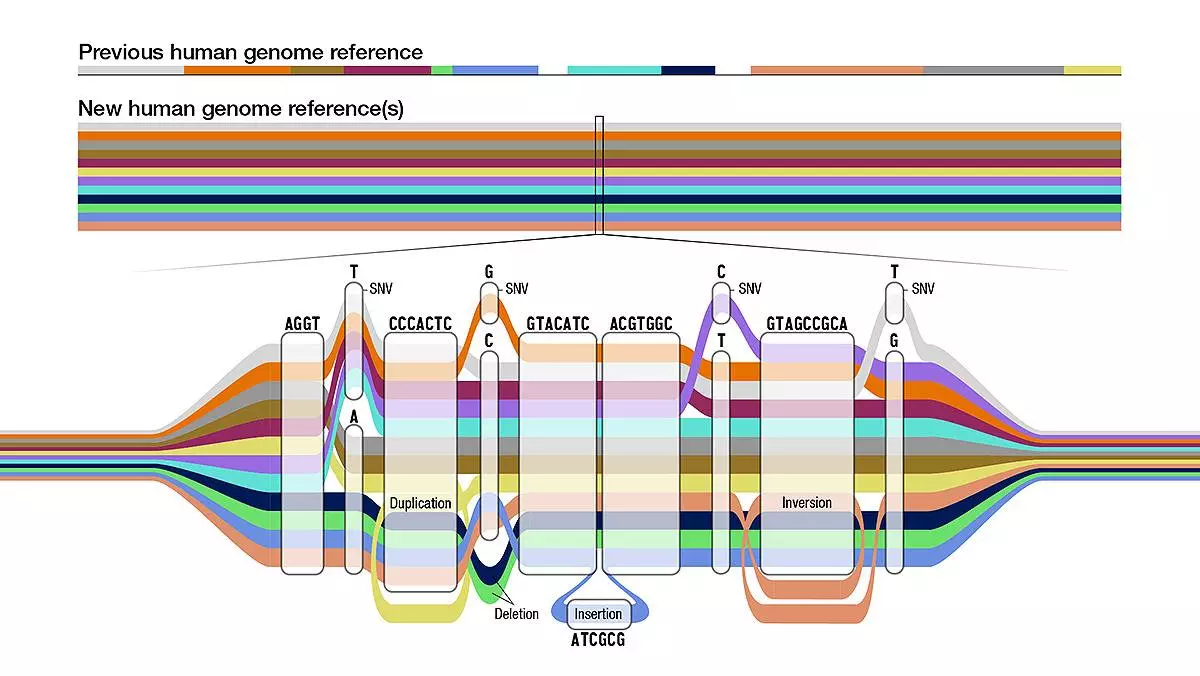
Para comprender estas diferencias genómicas, los científicos han creado sucesivas secuencias del genoma humano de referencia (llamado GRCh38) mediante fusiones digitales para usarlas como un "estándar" con el que comparar, lo que ayuda a alinear, ensamblar y estudiar otras secuencias de nuestro genoma.
A pesar de su importancia y continuas mejoras, GRCh38 presenta limitaciones a la hora representar la variabilidad de la especie humana, ya que consta de genomas de solo unas 20 personas, y la mayor parte de la secuencia de referencia es de solo una de ellas.

El pangenoma humano ofrece una colección más completa y sofisticada de secuencias genómicas que capta mejor la diversidad humana
Ahora, el Consorcio de Referencia del Pangenoma Humano (HPRC, por sus siglas en inglés) publica en la revista Nature una nueva y sofisticada colección de secuencias que mejora ese genoma "estándar" y recoge una diversidad sustancialmente mayor de la que se disponía hasta ahora. Se trata de un novedoso pangenoma de referencia.
De momento se presenta el primer borrador, que incluye secuencias genómicas de 47 personas de diversas partes del mundo y con ancestros diferentes (africanos, americanos, asiáticos y europeos), pero los investigadores pretenden aumentar ese número hasta 350 a mediados del año 2024. Como las personas llevamos los cromosomas en parejas, la referencia actual incluye 94 secuencias genómicas distintas y el objetivo es alcanzar 700 diferentes cuando acabe el proyecto.
Más de 100 millones de nuevas 'letras' en el ADN
Respecto al genoma humano de referencia, el pangenoma añade 119 millones de pares de bases o letras en el ADN y 1115 duplicaciones de genes (mutaciones en las que se duplica una región de ADN que contiene un gen), y aumenta la cantidad de variantes estructurales detectadas en un 104%, lo que brinda una imagen más completa de la diversidad genética dentro del genoma humano.

Se han usado secuencias genómicas de 47 personas ancestralmente diversas, pero ese número ascenderá a 350 en el año 2024
"Desde que se publicó el borrador del primer genoma humano, múltiples proyectos han trabajado en mejorar su calidad e ir completando esta referencia (por ejemplo con el reciente proyecto Telomere-to-Telomere, T2T). No obstante, una referencia única y lineal sigue sin modelar correctamente la diversidad genómica de nuestra especie, ya que existen múltiples variantes genómicas que no son comunes a todas las personas", explica a SINC uno de los muchos autores que han participado en este trabajo, Santiago Marco Sola, de la Universidad Autónoma de Barcelona.
"La solución propuesta ha sido modelar una referencia no-lineal que contenga las variaciones genómicas que existen en la población –aclara–, considerando la diversidad genómica de nuestra especie. Esto se denomina pangenoma y utiliza una estructura de grafo (o diagrama) para modelar las variaciones genómicas que se dan en diferentes individuos".
Ayuda de los supercomputadores
Marco Sola, también adscrito al Barcelona Supercomputing Center (BSC-CNS), destaca que este proyecto no sería posible sin los supercomputadores: "Si la construcción de una referencia genómica lineal (como GRCh38) requiere alinear y ensamblar cientos de miles de millones de bases de ADN, la de una referencia pangenómica necesita procesar varios órdenes de magnitud más de información".

En el superordenador MareNostrum 4 del BSC-CNS se han desarrollado métodos que luego se han incorporado al proyecto del pangenoma, aunque el cómputo y procesamiento de los resultados finales presentados ahora se ha realizado en otras infraestructuras internacionales de supercomputación.
Aplicaciones en biomedicina y salud
"La referencia del pangenoma humano nos permitirá representar decenas de miles de nuevas variantes genómicas en regiones del genoma que antes eran inaccesibles", subraya el coautor e investigador Wen-Wei Liao de la Universidad de Yale (EE UU), "y con ella podemos acelerar la investigación clínica, al mejorar nuestra comprensión del vínculo entre los genes y los rasgos de la enfermedad".
"Todo el mundo tiene un genoma único, por lo que el uso de una sola secuencia genómica de referencia para cada persona puede generar inequidades en los análisis genómicos", apunta el coautor Adam Phillippy, del Instituto Nacional de Investigación del Genoma Humano (NHGRI, parte de los National Institutes of Health de EEUU) desde donde se lidera este proyecto, "y por ejemplo, predecir una enfermedad genética podría no funcionar tan bien para alguien cuyo genoma es más diferente del genoma de referencia".

Los investigadores básicos y los médicos que utilizan la genómica necesitan acceder a una secuencia de referencia como esta que refleje la diversidad de la población humana
De ahí la importancia del nuevo pangenoma. "Los investigadores básicos y los médicos que utilizan la genómica necesitan acceder a una secuencia de referencia que refleje la notable diversidad de la población humana. Esto ayudará a que la referencia sea útil para todas las personas, lo que ayudará a reducir las posibilidades de propagar las disparidades en la salud", señala Eric Green, director del NHGRI.
"La creación y mejora de una referencia del pangenoma humano se alinea con el objetivo de nuestro instituto de luchar por la diversidad global en todos los aspectos de la investigación genómica, que es crucial para avanzar en el conocimiento genómico e implementar la medicina genómica de manera equitativa", añade.
Ética en el proyecto
En línea con este esfuerzo, el Consorcio de Referencia del Pangenoma Humano incluye un grupo de ética que trata de anticipar los retos que puedan surgir y guiar el consentimiento informado de los participantes, priorizar el estudio de diferentes muestras y explorar problemas regulatorios relacionados con la adopción clínica, así como trabajar con expertos internacionales y comunidades indígenas para incorporar sus secuencias genómicas.
El trabajo de este consorcio internacional cuenta con un presupuesto del unos 40 millones de dólares durante cinco años, lo que incluye los esfuerzos para crear la referencia del pangenoma humano, mejorar la tecnología de secuenciación del ADN, operar un centro de coordinación, llevar a cabo actividades de divulgación y generar recursos para que la comunidad científica pueda utilizar esta nueva referencia.
De hecho, junto al artículo principal de Nature se han publicado otros dos complementarios con resultados obtenidos gracias al borrador del pangenoma humano: un mapa con millones de variaciones de un solo nucleótido (SNV, diferencias de una sola letra en el ADN) desconocidas hasta ahora, y otro estudio sobre patrones de recombinación entre los brazos cortos de determinados cromosomas.
Los autores confían en que más investigaciones y avances en medicina personalizada aparecerán próximamente gracias al nuevo acceso al pangenoma humano.
¿Te ha resultado interesante esta noticia?
selección público





Comentarios
<% if(canWriteComments) { %> <% } %>Comentarios:
<% if(_.allKeys(comments).length > 0) { %> <% _.each(comments, function(comment) { %>-
<% if(comment.user.image) { %>
![<%= comment.user.username %>]() <% } else { %>
<%= comment.user.firstLetter %>
<% } %>
<% } else { %>
<%= comment.user.firstLetter %>
<% } %>
<%= comment.user.username %>
<%= comment.published %>
<%= comment.dateTime %>
<%= comment.text %>
Responder
<% if(_.allKeys(comment.children.models).length > 0) { %>
<% }); %>
<% } else { %>
- No hay comentarios para esta noticia.
<% } %>
Mostrar más comentarios<% _.each(comment.children.models, function(children) { %> <% children = children.toJSON() %>-
<% if(children.user.image) { %>
![<%= children.user.username %>]() <% } else { %>
<%= children.user.firstLetter %>
<% } %>
<% } else { %>
<%= children.user.firstLetter %>
<% } %>
<% if(children.parent.id != comment.id) { %>
en respuesta a <%= children.parent.username %>
<% } %>
<%= children.user.username %>
<%= children.published %>
<%= children.dateTime %>
<%= children.text %>
Responder
<% }); %>
<% } %> <% if(canWriteComments) { %> <% } %>